/* -MODULE----------------------------------------------------------------------
Phorward Foundation Toolkit
Copyright (C) 2006-2015 by Phorward Software Technologies, Jan Max Meyer
http://www.phorward-software.com ++ contact<at>phorward<dash>software<dot>com
All rights reserved. See LICENSE for more information.
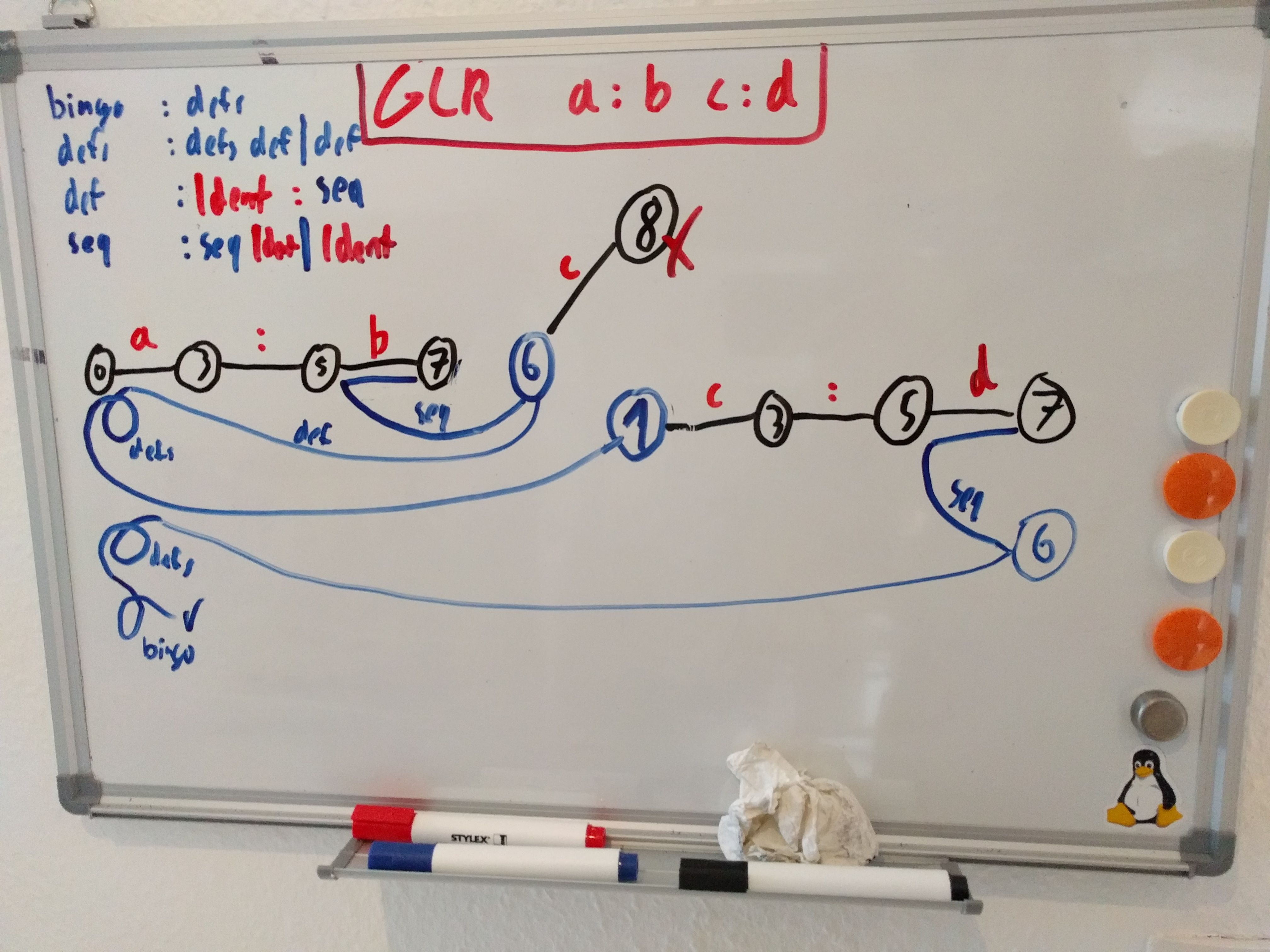
File: comp.gram.c
Usage: Self-hosted grammar for ppgram.
----------------------------------------------------------------------------- */
/*
This file was automatically generated by pinclude.
DO NOT CHANGE THIS FILE MANUALLY. IT WILL GO AWAY!
*/
#include "phorward.h"
void pp_bnf_define( ppgram* g )
{
ppsym* sym[ 49 ];
sym[ 1 ] = pp_sym_create( g, PPSYMTYPE_STRING, "kw_emit", "emit" );
sym[ 2 ] = pp_sym_create( g, PPSYMTYPE_STRING, "kw_noemit", "noemit" );
sym[ 3 ] = pp_sym_create( g, PPSYMTYPE_STRING, "kw_goal", "goal" );
sym[ 4 ] = pp_sym_create( g, PPSYMTYPE_STRING, "kw_ws", "whitespace" );
sym[ 5 ] = pp_sym_create( g, PPSYMTYPE_STRING, "kw_emitall", "emitall" );
sym[ 6 ] = pp_sym_create( g, PPSYMTYPE_STRING, "kw_emitnone", "emitnone" );
sym[ 7 ] = pp_sym_create( g, PPSYMTYPE_STRING, "kw_lrec", "lrec" );
sym[ 8 ] = pp_sym_create( g, PPSYMTYPE_STRING, "kw_rrec", "rrec" );
sym[ 9 ] = pp_sym_create( g, PPSYMTYPE_REGEX, "ws", "[\\t\\n\\r ]+" );
sym[ 9 ]->flags |= PPFLAG_WHITESPACE;
sym[ 10 ] = pp_sym_create( g, PPSYMTYPE_REGEX, "ccl", "'.*'" );
sym[ 10 ]->emit = 1;
sym[ 11 ] = pp_sym_create( g, PPSYMTYPE_REGEX, "string", "\".*\"" );
sym[ 11 ]->emit = 2;
sym[ 12 ] = pp_sym_create( g, PPSYMTYPE_REGEX, "regex", "/(\\\\.|[^/\\\\])*/" );
sym[ 12 ]->emit = 3;
sym[ 13 ] = pp_sym_create( g, PPSYMTYPE_REGEX, "ident", "[A-Z_a-z][0-9A-Z_a-z]*" );
sym[ 13 ]->emit = 10;
sym[ 14 ] = pp_sym_create( g, PPSYMTYPE_REGEX, "int", "[0-9]+" );
sym[ 14 ]->emit = 11;
sym[ 15 ] = pp_sym_create( g, PPSYMTYPE_CCL, "equal", "=" );
sym[ 16 ] = pp_sym_create( g, PPSYMTYPE_CCL, "percent", "%" );
sym[ 17 ] = pp_sym_create( g, PPSYMTYPE_CCL, "semicolon", ";" );
sym[ 18 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "symbol", (char*)NULL );
sym[ 18 ]->emit = 20;
sym[ 19 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "inline", (char*)NULL );
sym[ 19 ]->emit = 32;
sym[ 20 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "mod_kleene", (char*)NULL );
sym[ 20 ]->emit = 25;
sym[ 21 ] = pp_sym_create( g, PPSYMTYPE_CCL, (char*)NULL, "*" );
sym[ 22 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "mod_positive", (char*)NULL );
sym[ 22 ]->emit = 26;
sym[ 23 ] = pp_sym_create( g, PPSYMTYPE_CCL, (char*)NULL, "+" );
sym[ 24 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "mod_optional", (char*)NULL );
sym[ 24 ]->emit = 27;
sym[ 25 ] = pp_sym_create( g, PPSYMTYPE_CCL, (char*)NULL, "?" );
sym[ 26 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "modifier", (char*)NULL );
sym[ 27 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "sequence", (char*)NULL );
sym[ 28 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "alternative", (char*)NULL );
sym[ 28 ]->emit = 30;
sym[ 29 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "alternation", (char*)NULL );
sym[ 30 ] = pp_sym_create( g, PPSYMTYPE_CCL, (char*)NULL, "|" );
sym[ 31 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "emit", (char*)NULL );
sym[ 31 ]->emit = 42;
sym[ 32 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "int?", (char*)NULL );
sym[ 33 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "flag", (char*)NULL );
sym[ 33 ]->emit = 40;
sym[ 34 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "emitflag", (char*)NULL );
sym[ 35 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "flags", (char*)NULL );
sym[ 36 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "emitflag+", (char*)NULL );
sym[ 37 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "nontermdef", (char*)NULL );
sym[ 37 ]->emit = 31;
sym[ 38 ] = pp_sym_create( g, PPSYMTYPE_CCL, (char*)NULL, ":" );
sym[ 39 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "flags?", (char*)NULL );
sym[ 40 ] = pp_sym_create( g, PPSYMTYPE_CCL, (char*)NULL, "(" );
sym[ 41 ] = pp_sym_create( g, PPSYMTYPE_CCL, (char*)NULL, ")" );
sym[ 42 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "termdef", (char*)NULL );
sym[ 42 ]->emit = 35;
sym[ 43 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "gflag", (char*)NULL );
sym[ 43 ]->emit = 41;
sym[ 44 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "gflags", (char*)NULL );
sym[ 45 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "gflag+", (char*)NULL );
sym[ 46 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "definition", (char*)NULL );
sym[ 47 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "grammar", (char*)NULL );
g->goal = sym[ 47 ];
sym[ 48 ] = pp_sym_create( g, PPSYMTYPE_NONTERM, "definition+", (char*)NULL );
pp_prod_create( g, sym[ 18 ] ,
sym[ 19 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 18 ] ,
sym[ 12 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 18 ] ,
sym[ 11 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 18 ] ,
sym[ 10 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 18 ] ,
sym[ 13 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 20 ] ,
sym[ 18 ],
sym[ 21 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 22 ] ,
sym[ 18 ],
sym[ 23 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 24 ] ,
sym[ 18 ],
sym[ 25 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 26 ] ,
sym[ 18 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 26 ] ,
sym[ 24 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 26 ] ,
sym[ 22 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 26 ] ,
sym[ 20 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 27 ] ,
sym[ 26 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 27 ] ,
sym[ 27 ],
sym[ 26 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 28 ] , (ppsym*)NULL );
pp_prod_create( g, sym[ 28 ] ,
sym[ 27 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 29 ] ,
sym[ 28 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 29 ] ,
sym[ 29 ],
sym[ 30 ],
sym[ 28 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 32 ] ,
sym[ 14 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 32 ] , (ppsym*)NULL );
pp_prod_create( g, sym[ 31 ] ,
sym[ 1 ],
sym[ 32 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 33 ] ,
sym[ 4 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 33 ] ,
sym[ 3 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 33 ] ,
sym[ 2 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 34 ] ,
sym[ 33 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 34 ] ,
sym[ 31 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 36 ] ,
sym[ 36 ],
sym[ 34 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 36 ] ,
sym[ 34 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 35 ] ,
sym[ 16 ],
sym[ 36 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 35 ] ,
sym[ 35 ],
sym[ 16 ],
sym[ 36 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 39 ] ,
sym[ 35 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 39 ] , (ppsym*)NULL );
pp_prod_create( g, sym[ 37 ] ,
sym[ 13 ],
sym[ 38 ],
sym[ 29 ],
sym[ 39 ],
sym[ 17 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 19 ] ,
sym[ 40 ],
sym[ 29 ],
sym[ 41 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 42 ] ,
sym[ 13 ],
sym[ 15 ],
sym[ 12 ],
sym[ 39 ],
sym[ 17 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 42 ] ,
sym[ 13 ],
sym[ 15 ],
sym[ 11 ],
sym[ 39 ],
sym[ 17 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 42 ] ,
sym[ 13 ],
sym[ 15 ],
sym[ 10 ],
sym[ 39 ],
sym[ 17 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 43 ] ,
sym[ 8 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 43 ] ,
sym[ 7 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 43 ] ,
sym[ 6 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 43 ] ,
sym[ 5 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 45 ] ,
sym[ 45 ],
sym[ 43 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 45 ] ,
sym[ 43 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 44 ] ,
sym[ 16 ],
sym[ 45 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 44 ] ,
sym[ 44 ],
sym[ 16 ],
sym[ 45 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 46 ] ,
sym[ 44 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 46 ] ,
sym[ 42 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 46 ] ,
sym[ 37 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 48 ] ,
sym[ 48 ],
sym[ 46 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 48 ] ,
sym[ 46 ],
(ppsym*)NULL );
pp_prod_create( g, sym[ 47 ] ,
sym[ 48 ],
(ppsym*)NULL );
}