
Update 24.02.2018: Das was ich hier vorher geschrieben hatte war totaler Murks. Jetzt wälze ich erstmal nochmal die Paper dazu und dann sollte ich das nochmal ganz neu aufrollen…
So mal wieder nach längerer Zeit ein neues Posting hier. Muss mal wieder ein paar Gedanken sammeln. Beschäftige mich seit ca. zwei Wochen nun endlich mal mit GLR Parsern, obwohl ich in dem Buch Parsing Techniques von Grune und Jacobs, welches ich schon seit einiger Zeit sporadisch wälze, noch gar nicht in dem Kapitel angekommen bin (zzt. Kapitel 7.2 auf Seite 210, von ca. 640 Seiten). Aber das Parse-Verfahren habe ich mir schon mehrfach angeschaut, es aber nie wirklich umgesetzt.
Aber für die Umsetzung erstmal ein wenig Forschung betrieben…
…und einen (eigenen!) Algorithmus aufgebaut…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
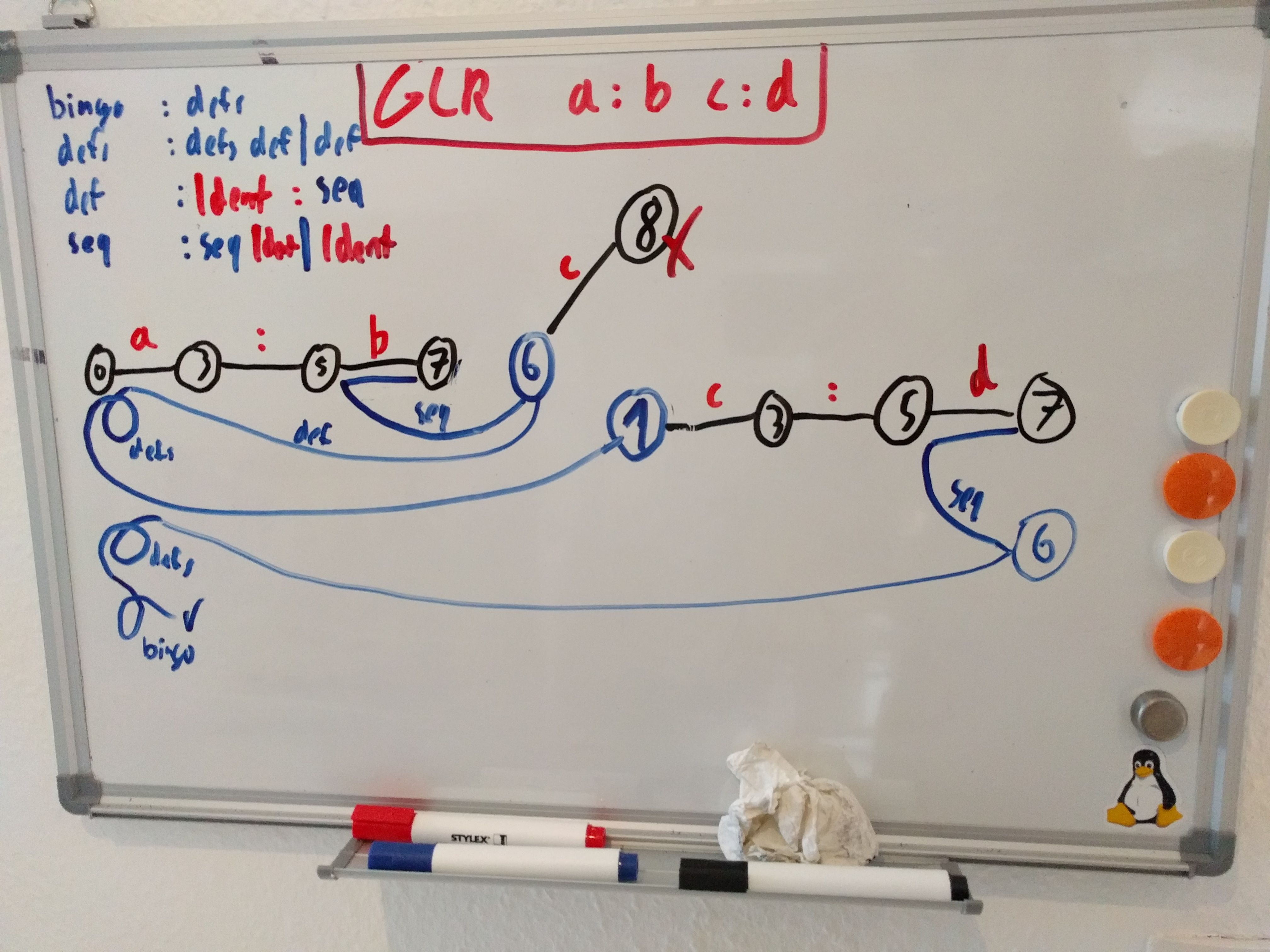
-- Grammar -- seq : seq Ident | Ident def : Ident ':' seq defs : defs def | def bingo$: defs -- State 0 -- Kernel (1): bingo : . defs Epsilon (0): (empty) -> Shift on 'Ident', goto state 3 -> Goto state 1 on 'defs' -> Goto state 2 on 'def' -- State 1 -- Kernel (2): bingo : defs . { >&eof< } defs : defs . def Epsilon (0): (empty) -> Shift on 'Ident', goto state 3 <- Reduce on '&eof' by production 'bingo : defs' -> Goto state 4 on 'def' -- State 2 -- Kernel (1): defs : def . { >&eof< >Ident< } Epsilon (0): (empty) <- Reduce on '&eof' by production 'defs : def' <- Reduce on 'Ident' by production 'defs : def' -- State 3 -- Kernel (1): def : Ident . : seq Epsilon (0): (empty) -> Shift on ':', goto state 5 -- State 4 -- Kernel (1): defs : defs def . { >&eof< >Ident< } Epsilon (0): (empty) <- Reduce on '&eof' by production 'defs : defs def' <- Reduce on 'Ident' by production 'defs : defs def' -- State 5 -- Kernel (1): def : Ident : . seq Epsilon (0): (empty) -> Shift on 'Ident', goto state 7 -> Goto state 6 on 'seq' -- State 6 -- Kernel (2): def : Ident : seq . { >&eof< >Ident< } seq : seq . Ident Epsilon (0): (empty) -> Shift on 'Ident', goto state 8 <- Reduce on '&eof' by production 'def : Ident : seq' <- Reduce on 'Ident' by production 'def : Ident : seq' -- State 7 -- Kernel (1): seq : Ident . { >&eof< >Ident< } Epsilon (0): (empty) <- Reduce on '&eof' by production 'seq : Ident' <- Reduce on 'Ident' by production 'seq : Ident' -- State 8 -- Kernel (1): seq : seq Ident . { >&eof< >Ident< } Epsilon (0): (empty) <- Reduce on '&eof' by production 'seq : seq Ident' <- Reduce on 'Ident' by production 'seq : seq Ident' |
…der auch direkt unter Verwendung eines Graph-structured Stack arbeitet. Ich finde bei diesen Informatikbüchern ja immer interessant, dass manche Sache sehr theoretisch behandelt werden. Da wird dann einfach mal der komplette Parse-Stack kopiert und nach einem missglückten Shift dann komplett verworfen. Naja, wenn man das ganze implementieren will, noch dazu in einer Programmiersprache ohne Garbage Collection, dann kopiert man sicherlich nicht erstmal alle Element eines dynamisch allokierten Stacks und deren dynamsiche Stack-Elemente, um diese dann einen Shift später wieder frei zu geben. Mega-Ineffizient.
Naja, und nachdem ich zuerst dachte, es könnte auch klappen, wenn man den Lookahead global hält, wurde ich eines besseren belehrt, denn das geht (rein logisch gesehen) nicht. Es scheint aber so ungefähr zu funktionieren, wie hier, nur das da momentan noch das Stack merging fehlt (zusammenführen mehrerer Stack-Stränge bei einem gemeinsamen Shift). Dazu muss ich aber erstmal noch ein bisschen forschen und testen.
Was es jetzt noch zu lösen gilt (und wo warscheinlich die meiste arbeit drin steckt):
- Einen eindeutigen (den besten?) Syntaxbaum aus den (bei ambigen Grammatiken dann mehrpfadigen) Parse-Graphen erzeugen
- Effiziente Garbage Collection
- Lookahead-Caching bzw. geht das nicht doch mit einem Lookahead?
Bin mal gespannt…